
布隆过滤器(Bloom Filter)是一个很长的二进制向量和一系列随机映射函数
用途:判断一个元素是否在一个集合中
严谨来说,应该是:判断某样东西一定不存在或可能存在
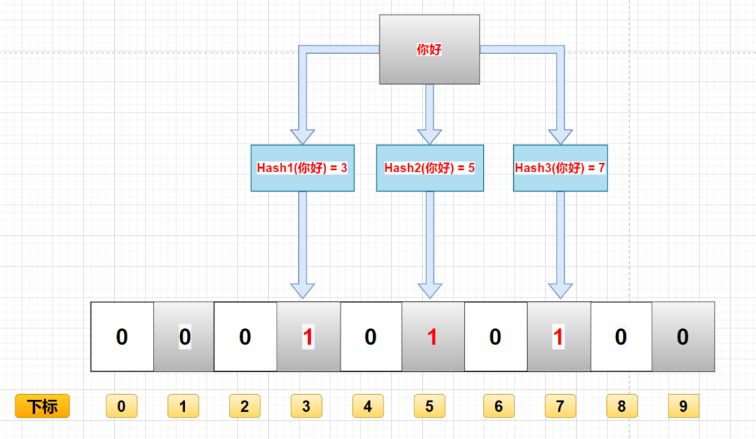
数据存入
- 经过K个哈希函数计算,返回K个计算出的hash值
- 这k个hash值映射到对应的k个数组下标
- 将二进制向量中这k个下标的对应数据改为1
数据查询
- 经过K个哈希函数计算该数据,算出k个hash值
- 以hash值为下标在二进制向量中找到对应的数据
- 若有一处的数据为0,则该数据不存在,否则说明数据可能存在(并不是一定存在,有误判的可能)
参数选择
二进制向量的长度会影响误报率,长度越长,误报率越低
- 若长度太小,所有bit都置成1的话,那么查询任何值都会返回“可能存在”,无法起到过滤的目的
- 若长度太大,则可能会造成空间浪费
哈希函数的个数也会影响误报率,函数个数越多,误报率越低
- 若函数个数太多,则二进制向量置1的速度会变得很快,这样布隆过滤器的效率会变低
- 若函数个数太少,则误报率变高
参数的选取公式:
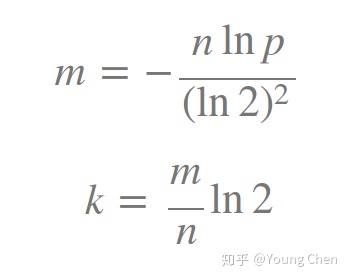
k为哈希函数个数,m为布隆过滤器长度,n为插入元素的个数,p为误报率
总结
优点:
- 占用空间小(存储的是二进制数据)
- 查询速度快,时间复杂度为O(k)
- 保密性很好,不存储任何原始数据,只有二进制数据
缺点:
- 存在误判的可能(不同的数据可能映射到二进制向量中的相同位置)
- 删除困难,也是因为上述的理由
与HashMap的比较:
HashMap速度也很快,但占用空间太大,因为有负载因子的存在,为了避免哈希冲突,空间是没办法用满的,会造成大量的空间浪费。使用布隆过滤器可以在不牺牲查找速度的同时,降低空间消耗,代价就是判断并不完全准确
应用场景:
- URL黑名单过滤
- 解决缓存穿透的问题
- …