简介
ConcurrentLinkedQueue是高并发环境中性能最好的队列
要想队列保证线程安全,有两种实现方式
- 阻塞算法:锁
- 非阻塞算法:循环CAS
在队列中,BlockingQueue是阻塞算法的典型实现(使用锁来保证线程安全),而ConcurrentLinkedQueue则是非阻塞算法的典型实现(使用CAS保证线程安全)
原理
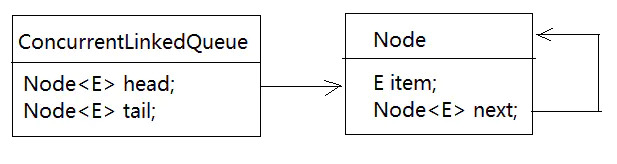
Node节点
static final class Node<E> {
volatile E item;
volatile Node<E> next;
// 利用CAS操作向后添加一个节点
void appendRelaxed(Node<E> next) {
NEXT.set(this, next);
}
// 利用CAS操作设置值(cmp是期望值,val是要设置的值)
boolean casItem(E cmp, E val) {
return ITEM.compareAndSet(this, cmp, val);
}
}
head和tail
transient volatile Node<E> head;
private transient volatile Node<E> tail;
// 初始时,head和tail都指向一个空节点
public ConcurrentLinkedQueue() {
head = tail = new Node<E>();
}
CoucurrentLinkedQueue规定了如下几个不变性:
- 最后一个元素的next为null
- 队列中所有未删除的节点的item都不能为null,且都能从head节点遍历到
- 对于要删除的节点,不是直接将其设置为null,而是先将其item域设置为null(迭代器会跳过item为null的节点)
- head和tail并不一定指向真正的头和尾节点,因为它们的更新有滞后性,每次更新会跳跃两个元素
入队
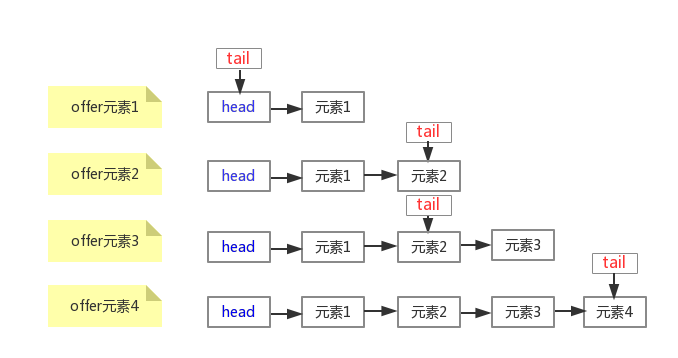
public boolean offer(E e) {
// 确保值不为空,且创建新节点
final Node<E> newNode = new Node<E>(Objects.requireNonNull(e));
// 循环进行CAS操作,直至成功为止(因为CAS操作有可能失败)
// t:指向tail
// p、q:进行遍历使用的指针,p在前,q在后
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// p是最后一个节点的情况,此时q为null
if (NEXT.compareAndSet(p, null, newNode)) {
// 将新创建的节点添加到链表末尾
if (p != t)
// 当p和t不相等,也就是新创建的节点和原tail中间隔着一个元素时,才更新tail,相当于tail的1次更新跨越2个元素
TAIL.weakCompareAndSet(this, t, newNode);
return true;
}
// CAS失败,再次尝试
}
else if (p == q)
// 遇到了哨兵节点,从head开始重新遍历,或者如果有其他线程修改了tail,就使用这个刚被修改的tail
// t != (t = tail)是为了检查在执行过程中,tail是否被其他线程修改,如果是,则进行一次“打赌”,将刚被修改的tail当作链表末尾
// 这样就可以提高性能,省去了重新查找tail的开销
p = (t != (t = tail)) ? t : head;
else
// p不是最后一个节点的情况(添加了节点,tail未更新的情况)
// 将p不断推进到链表末尾
p = (p != t && t != (t = tail)) ? t : q;
}
}
在JDK 1.7的实现中,doug lea使用hops变量来控制并减少tail节点的更新频率,并不是每次节点入队后都将 tail节点更新成尾节点,而是当tail节点和尾节点的距离大于等于常量HOPS的值(默认等于1)时才更新tail节点,tail和尾节点的距离越长使用CAS更新tail节点的次数就会越少,但是距离越长带来的负面效果就是每次入队时定位尾节点的时间就越长,因为循环体需要多循环一次来定位出尾节点,但是这样仍然能提高入队的效率,因为从本质上来看它通过增加对volatile变量的读操作来减少了对volatile变量的写操作,而对volatile变量的写操作开销要远远大于读操作,所以入队效率会有所提升。
在JDK 1.8的实现中,tail的更新时机是通过p和t是否相等来判断的,其实现结果和JDK 1.7相同,即当tail节点和尾节点的距离大于等于1时,更新tail。
出队
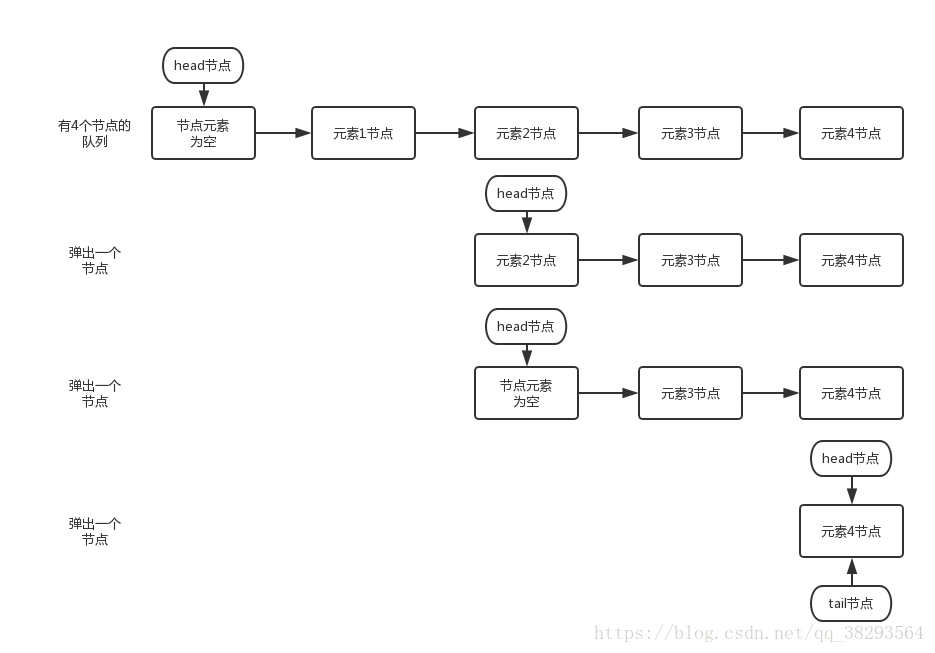
public E poll() {
// 循环进行CAS操作
restartFromHead: for (;;) {
for (Node<E> h = head, p = h, q;; p = q) {
final E item;
if ((item = p.item) != null && p.casItem(item, null)) {
// p的item值不为null,说明是有效节点,并使用CAS将p的item置为null
if (p != h)
// head的1次更新会跨越2个元素(当head指向的节点中元素为null,才更新head)
// 更新head的同时,原先的head成为哨兵节点(next指向自己的节点)
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
else if ((q = p.next) == null) {
// 链表为空,则更新head,并返回null
updateHead(h, p);
return null;
}
else if (p == q)
// 遇到哨兵节点,重新从head开始遍历
continue restartFromHead;
}
}
}
总结
- 使用CAS原子指令处理对数据的并发访问
- head和tail并非总是指向队列的头和尾节点,也就是说允许队列处于不一致状态。这个特性把入队、出队时,原本需要一起原子化执行的两个步骤分离开来,缩小了入队、出队时需要原子化更新值的范围到唯一变量,而head和tail的更新使用批处理的方式完成(一次更新2步)。这样的做法减少了入队、出队操作的开销,提高了入队、出队的性能
- 因为队列有时会处于不一致状态,所以ConcurrentLinkedQueue 使用三个不变式来维护非阻塞算法的正确性